Cloud Admin Panel
Project overview
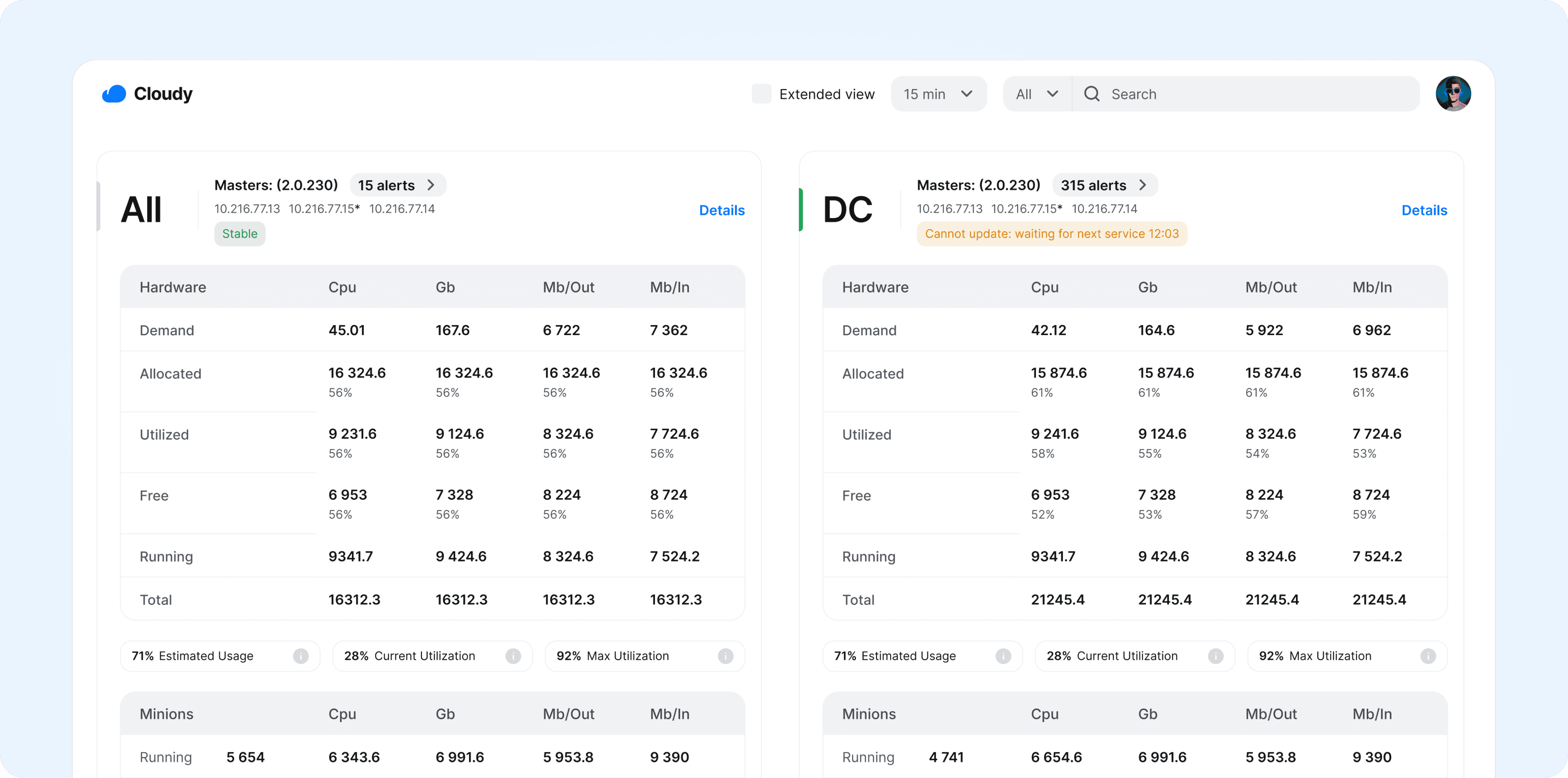
Cloud is an internal infrastructure management platform for monitoring data centers, compute resources, services, instances, volumes, devices, and alerts. The product gives infrastructure teams a single workspace to track system health, understand capacity, and quickly drill down into affected resources.
Challenge
As infrastructure grew across multiple data centers, teams needed a faster way to understand system health, detect overload risks, and investigate issues without switching between separate tools.
The challenge was to turn dense technical data into a clear admin experience for monitoring capacity, alerts, services, and resource-level details.
Goals
We focused on making infrastructure status easier to understand, reducing manual checks, and helping teams act faster during incidents and capacity planning.






Constraints
Dense Operational Data
We needed to show many metrics, states, and resources without overwhelming users.
System Constraints
Solutions had to fit existing components, data structures, and technical limitations.
Limited Research Access
Due to NDA restrictions, research was based on internal insights and stakeholder feedback.
PrimeVue & BODS Constraints
The interface had to stay aligned with existing components and system rules.
Key Insights
Key desicions
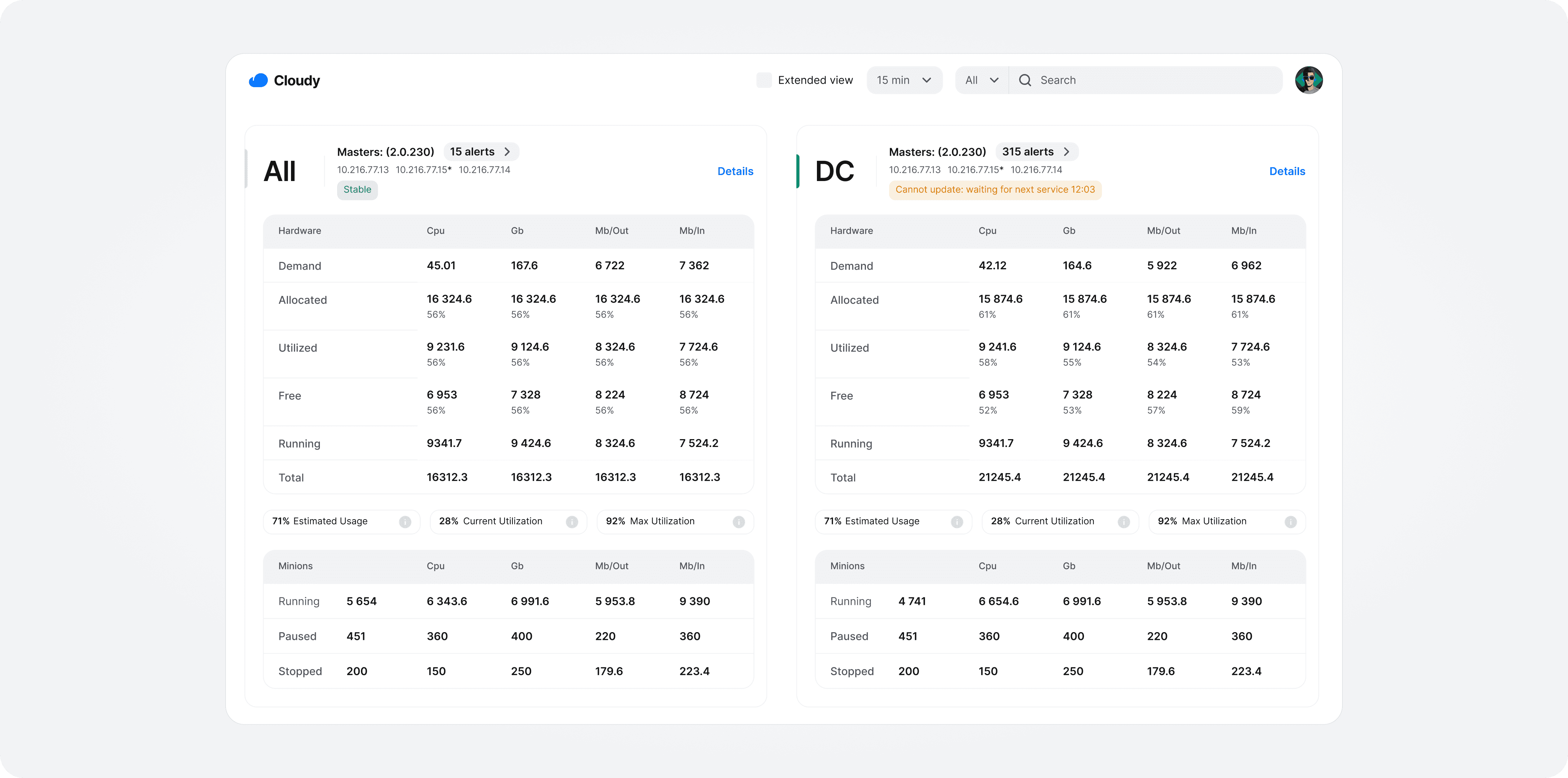
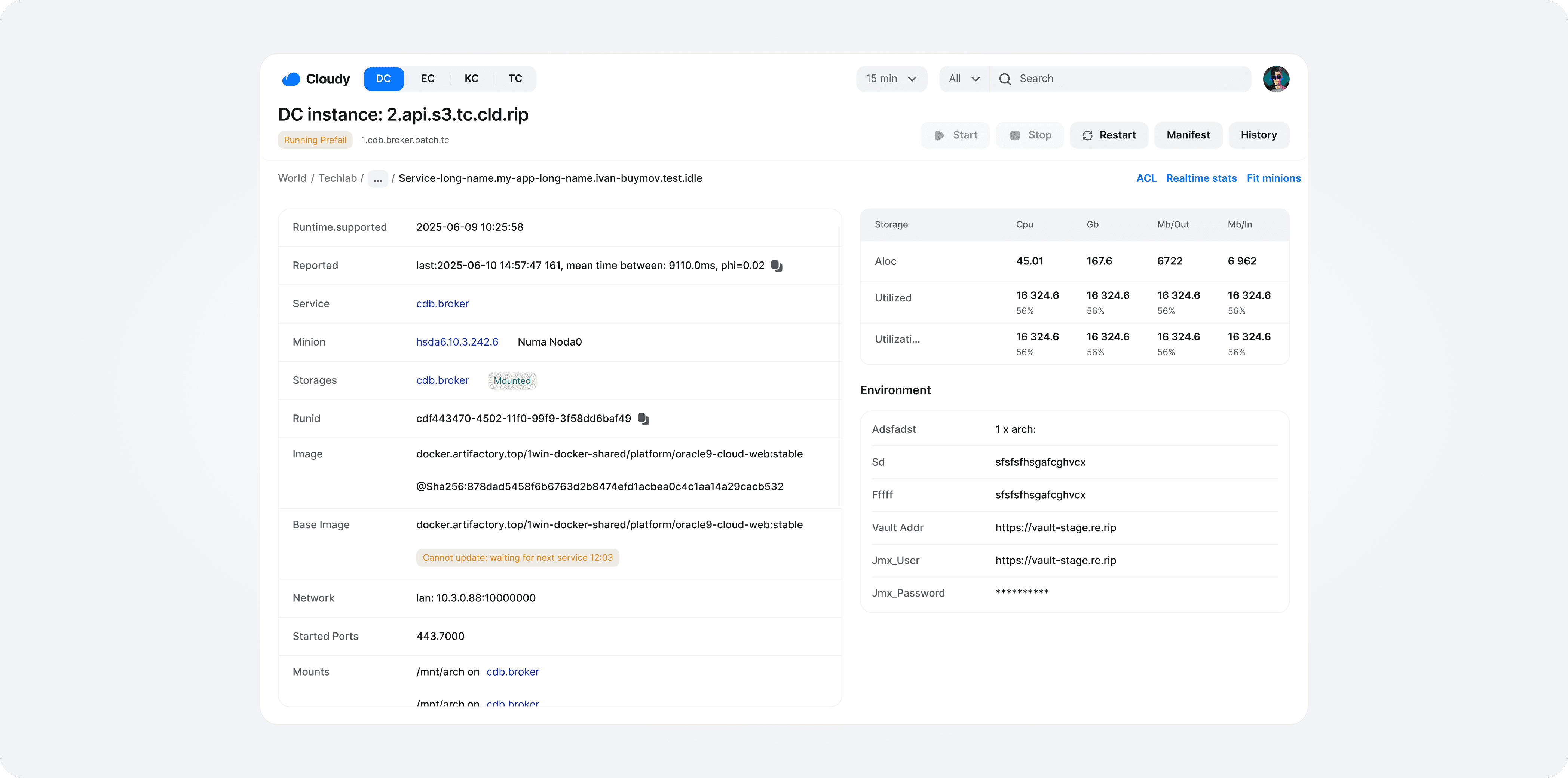
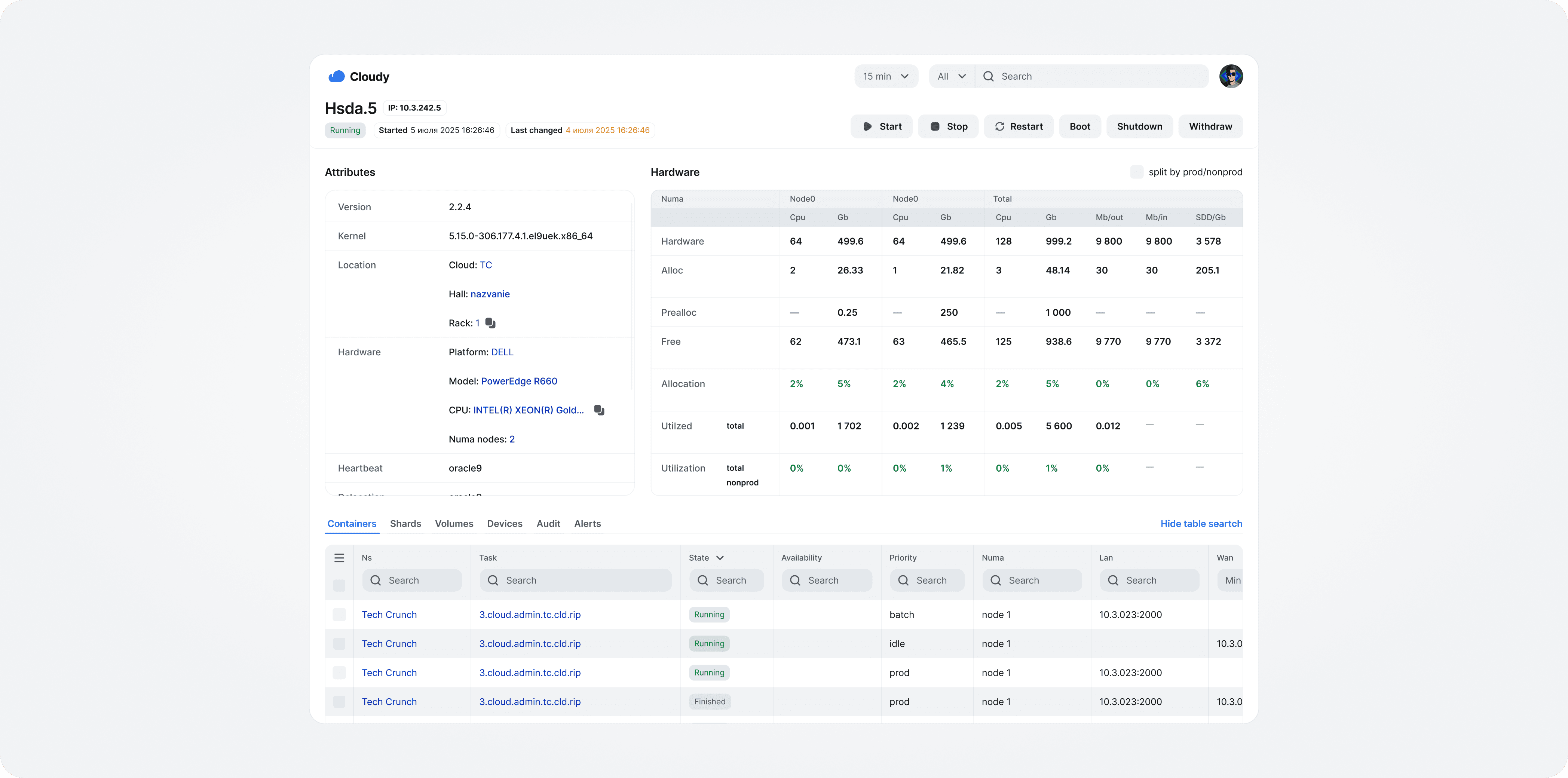
To make complex infrastructure easier to operate, I focused on two core interactions: monitoring capacity at a glance and drilling down into affected resources.
Engineers can scan data centers, spot overload risks, and open affected resources.
Engineers can search managed nodes, check their status, and run actions in context.
Final interface
The final design brings data centers, capacity, alerts, services, and resource-level controls into one workspace for infrastructure operations.
Impact
Based on employee interviews and internal feedback, the new admin panel helped teams investigate issues faster, reduce manual status checks, detect overload risks earlier, and review capacity with less effort.
Faster
issue investigation
Fewer manual
status checks
Faster
overload detection
Faster
capacity review